Now what?
What's the first thing you do when you get an unknown file?
Run file on it
$ file otter.gen
otter.gen: ASCII text
Check its size
$ ls -l otter.gen -rw-r--r-- 1 rowlings rowlings 2341 Apr 24 17:24 otter.gen
Human-readable size...
$ ls -lh otter.gen -rw-r--r-- 1 rowlings rowlings 2.3K Apr 24 17:24 otter.gen
Word, line, character count
$ wc otter.gen
130 251 2341 otter.gen
Run head on it
$ head otter.gen
1
-145.8953 60.63951
-145.8936 60.63902
-145.8931 60.63774
-145.8941 60.63768
-145.8922 60.63676
-145.8941 60.63651
-145.8976 60.63645
-145.8972 60.63480
-145.8955 60.63450
Run tail on it
$ tail -5 otter.gen
-145.8901 60.62465
-145.8901 60.62465
END
END
What are those END lines doing there?
more (or less)$ more otter.gen 1 -145.8953 60.63951 -145.8936 60.63902 -145.8931 60.63774 ... -145.8962 60.63878 -145.8965 60.64031 -145.8926 60.64104 END 2 -145.9652 60.61914 -145.9634 60.61841 -145.9599 60.61731 -145.9587 60.61780 -145.9587 60.61878 -145.9599 60.61902 -145.9587 60.61988 -145.9565 60.61939 -145.9577 60.61865 -145.9560 60.61792 -145.9595 60.61731 --More--(34%)
Then hit space for next page, q to quit, / to find, h for help.
less is an alternative pager to more with more features.
grep command
$ grep END otter.gen
END
END
END
END
$ grep -n END otter.gen
33:END
89:END
128:END
129:END
$ grep END otter.gen | wc -l
4
grep is great for filtering HUGE files
$ grep ^LA1 postcodes.txt > LA1-codes.txt
$ grep ^LA1 cases.txt | tr '[a-z]' '[A-Z]' | sed 's/FEMAIL/FEMALE/' | grep FEMALE > clean-uc-f.txt
$ sort cases.txt | uniq -c
1 LA1 Femail
2 LA1 Female
1 LA1 Male
1 LA2 Femail
1 LA2 Female
1 LA2 Maile
LA1 34243,22310 LA2 77394,12848 LA3 66100,26230
LA1 Femail LA1 Female LA1 Female LA1 Male LA2 Femail LA2 Female LA2 Maile
join:
$ join sort-cases.txt LA1-codes.txt
LA1 Femail 34243,22310
LA1 Female 34243,22310
LA1 Female 34243,22310
LA1 Male 34243,22310
LA2 Femail 77394,12848
LA2 Female 77394,12848
LA2 Maile 77394,12848
For each otter track:
Then an END mark
awk is a very useful text-file stream processing languagepattern {action}Print all lines that don't have two fields:
$ awk 'NF!=2' otter.gen
1
END
2
END
3
END
END
Print message where second field is greater than some value:
$ awk '$2 > 60.64 {print NR," large Y ",$0}' otter.gen
31 large Y -145.8965 60.64031
32 large Y -145.8926 60.64104
98 large Y -145.9250 60.64104
99 large Y -145.9233 60.64153
Use the result of grep -n END otter.gen to get the line numbers:
$ grep -n END otter.gen
33:END
89:END
128:END
129:END
Use two awk rules:
BEGIN {n=0} runs before the first line, and sets n to 0.{print $1 - n; n=$1 } runs on every line and prints the difference between n and the first field.
It then updates n to that value:
$ grep -n END otter.gen | awk -F: 'BEGIN {n=0} ; {print $1 - n; n=$1 } '
33
56
39
1
$0=="END" && id != "END" {print id,dist}
NF==1 {dist=0; first=1; id=$1}
NF==2 && first==1 {
x1=$1
y1=$2
first = 0
}
NF==2 {x2=$1
y2=$2
dist = dist + sqrt((x2-x1)^2 + (y2-y1)^2)
y1 = y2
x1 = x2
}
Then run:
$ awk -f pathlength.awk otter.gen
1 0.070923
2 0.102671
3 0.110943
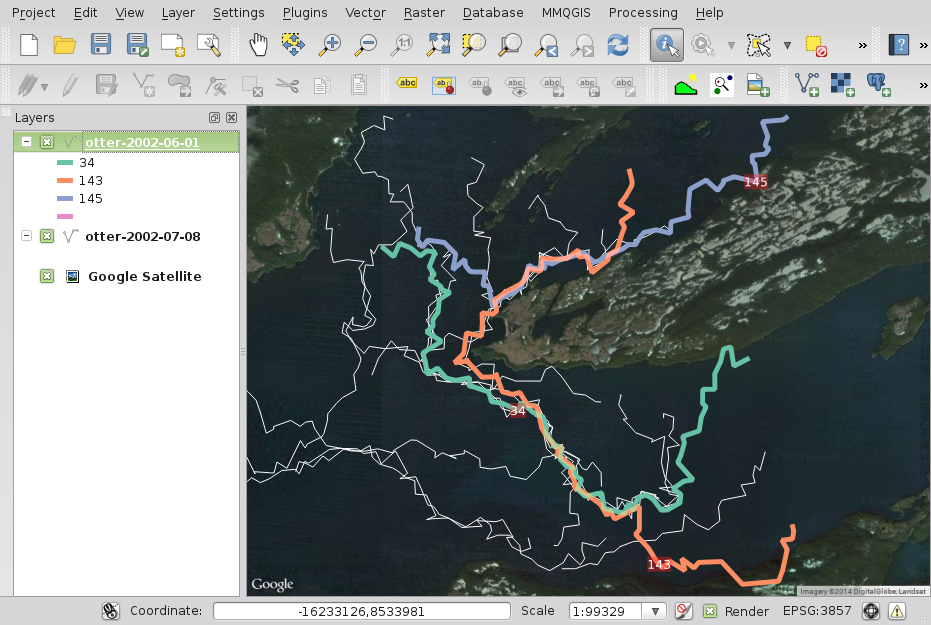
$ ogrinfo otter.gen
Had to open data source read-only.
INFO: Open of `otter.gen'
using driver `ARCGEN' successful.
1: otter (Line String)
$ ogrinfo -so -al otter.gen
Had to open data source read-only.
INFO: Open of `otter.gen'
using driver `ARCGEN' successful.
Layer name: otter
Geometry: Line String
Feature Count: 3
Extent: (-145.965700, 60.615840) - (-145.890100, 60.641530)
Layer SRS WKT:
(unknown)
ID: Integer (0.0)
$ ogrinfo -al otter.gen
Had to open data source read-only.
INFO: Open of `otter.gen'
using driver `ARCGEN' successful.
Layer name: otter
Geometry: Line String
Feature Count: 3
Extent: (-145.965700, 60.615840) - (-145.890100, 60.641530)
Layer SRS WKT:
(unknown)
ID: Integer (0.0)
OGRFeature(otter):0
ID (Integer) = 1
LINESTRING (-145.8953 60.63951,-145.8936 60.63902,...1,-145.8926 60.64104)
OGRFeature(otter):1
ID (Integer) = 2
LINESTRING (-145.9652 60.61914,-145.9634 60.61841,....
...
$ ogr2ogr -s_srs "+init=epsg:4326" -t_srs "+init=epsg:4326" otter.shp otter.gen $ ogrinfo -so -al otter.shp INFO: Open of `otter.shp' using driver `ESRI Shapefile' successful. Layer name: otter Geometry: Line String Feature Count: 3 Extent: (-145.965700, 60.615840) - (-145.890100, 60.641530) Layer SRS WKT: GEOGCS["GCS_WGS_1984", DATUM["WGS_1984", SPHEROID["WGS_84",6378137,298.257223563]], PRIMEM["Greenwich",0], UNIT["Degree",0.017453292519943295]] ID: Integer (10.0)
$ ogr2ogr -s_srs "+init=epsg:4326" -t_srs "+init=epsg:4326" otter.shp otter.gen
for each "generate" file...Use echo to print things:
$ echo "Hello World" Hello World $ echo$HOME /home/rowlings
Loop over files and print name:
$ for f in *.gen ; do echo $f ; done
otter-2002-06-01.gen
otter-2002-06-02.gen
otter-2002-06-03.gen
otter-2002-06-04.gen
otter-2002-06-05.gen
...
How do we create the output shapefile name?
$ for f in *.gen ; do echo ${f%.gen}.shp ${f:6:10} ; done
otter-2002-06-01.shp 2002-06-01
otter-2002-06-02.shp 2002-06-02
otter-2002-06-03.shp 2002-06-03
otter-2002-06-04.shp 2002-06-04
otter-2002-06-05.shp 2002-06-05
otter-2002-06-06.shp 2002-06-06
otter-2002-06-07.shp 2002-06-07
...
$ ogr2ogr -s_srs "+init=epsg:4326" -t_srs "+init=epsg:4326" otter.shp otter.gen
for each "generate" file...$ for f in *.gen ; do > ogr2ogr -s_srs "+init=epsg:4326" -t_srs "+init=epsg:4326" ${f%.gen}.shp $f > done
We want to:
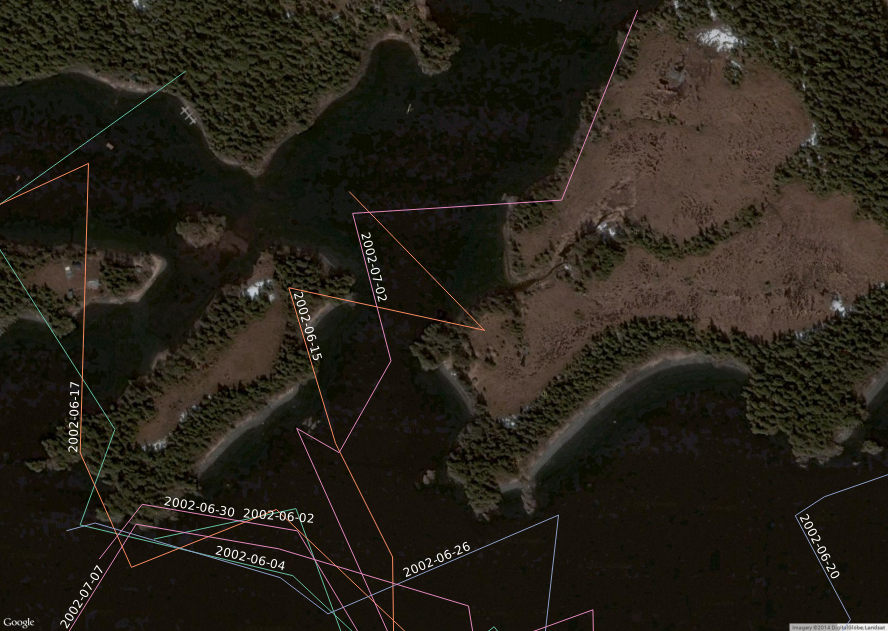
$ ogrinfo otter-2002-06-01.shp -sql "ALTER TABLE otter-2002-06-01 ADD COLUMN day character(15)"
$ ogrinfo otter-2002-06-01.shp -dialect SQLite -sql "UPDATE 'otter-2002-06-01' SET day='2002-06-01'"
$ ogrinfo -geom=NO -al otter-2002-06-01.shp
INFO: Open of `otter-2002-06-01.shp'
using driver `ESRI Shapefile' successful.
Layer name: otter-2002-06-01
Geometry: Line String
Feature Count: 3
[etc]
ID: Integer (10.0)
day: String (15.0)
OGRFeature(otter-2002-06-01):0
ID (Integer) = 34
day (String) = 2002-06-01
OGRFeature(otter-2002-06-01):1
ID (Integer) = 143
day (String) = 2002-06-01
OGRFeature(otter-2002-06-01):2
ID (Integer) = 145
day (String) = 2002-06-01
for genfile in *.gen ; do
echo "Processing " $genfile
layer="${genfile%.gen}"
shapefile="${layer}.shp"
day="${genfile:6:10}"
ogr2ogr -s_srs "+init=epsg:4326" -t_srs "+init=epsg:4326" $shapefile $genfile
ogrinfo $shapefile -sql "ALTER TABLE $layer ADD COLUMN day character(15)"
ogrinfo $shapefile -dialect SQLite -sql "UPDATE '$layer' SET day='$day'"
done
ogr2ogr alltracks.shp part-1.shp ogr2ogr -update -append alltracks.shp part-2.shp -nln alltracks ogr2ogr -update -append alltracks.shp part-3.shp -nln alltracks ogr2ogr -update -append alltracks.shp part-4.shp -nln alltracks ...
for f in *.shp ; do
if [ -f alltracks.shp ] ; then
echo merging $f
ogr2ogr -update -append alltracks.shp $f -nln alltracks
else
echo starting with $f
ogr2ogr alltracks.shp $f
fi
done
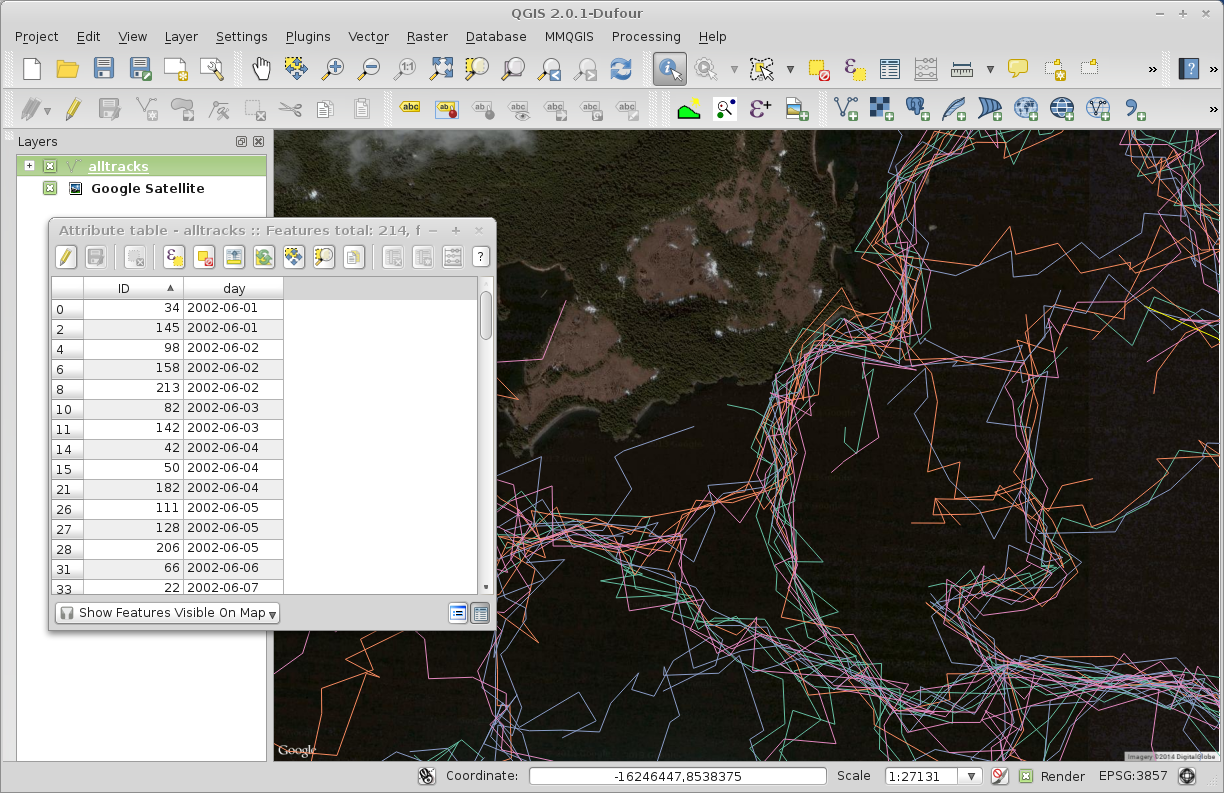
$ ogrinfo -geom=NO -al alltracks.shp | more
INFO: Open of `alltracks.shp'
using driver `ESRI Shapefile' successful.
Layer name: alltracks
Geometry: Line String
Feature Count: 214
Extent: (-145.981367, 60.586132) - (-145.817827, 60.649236)
Layer SRS WKT:
GEOGCS["GCS_WGS_1984",
DATUM["WGS_1984",
SPHEROID["WGS_84",6378137,298.257223563]],
PRIMEM["Greenwich",0],
UNIT["Degree",0.017453292519943295]]
ID: Integer (10.0)
day: String (15.0)
OGRFeature(alltracks):0
ID (Integer) = 34
day (String) = 2002-06-01
OGRFeature(alltracks):1
ID (Integer) = 143
day (String) = 2002-06-01
OGRFeature(alltracks):2
ID (Integer) = 145
day (String) = 2002-06-01
...